背景知识
Stable Diffusion web UI
https://github.com/AUTOMATIC1111/stable-diffusion-webui
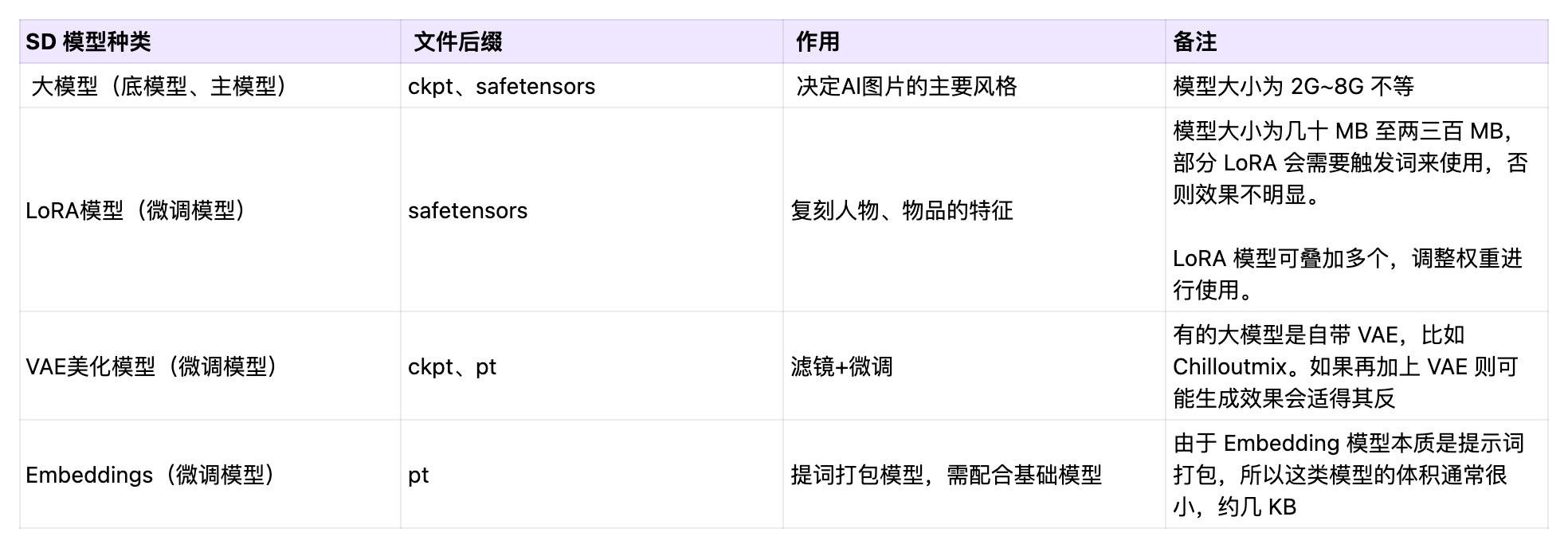
SD 中有各种各样的模型,除了大模型,还可以搭配其他模型对图片进行微调,这么多模型种类,到底是做什么用的,如何区分呢?不同的基础模型,其画风和擅长的领域会有侧重。
LoRA 训练步骤
LoRA 训练对显卡有一定要求, 同时需要安装一些方便训练的软件。SD1.5 版本的底模 6G 显存勉强可用,8G 显存就可以比较流畅的生成 图片和炼制 LoRA,12G 可以流畅的使用 Dreambooth 微调大模型。
LoRA 训练可以划分为五个步骤:

1. 确定目的
可以简单地划分为两类:具象类和泛化类。
具象类:如一个物体、 一种姿态、一种服装、一个人物、某个特定元素等
泛化类:如某种场景、某种艺术风格、色彩风格等

2. 收集数据集
「大模型的选择」和「图片质量」都是收集数据集的关键。收集素材阶段,我们仍然按照第一步中的训练目的,分为具象类和泛化类。
注意版权,不要使用有版权的图片,慎用肖像。

3. 数据集预处理
处理数据集包括:优化素材清晰度、统一素材尺寸、生成标签、以及优化标签。
1)批量超分辨率

2)批量剪裁

3)使用 sdwebui 的 tag editor 插件打标
https://github.com/toshiaki1729/stable-diffusion-webui-dataset-tag-editor
安装 Dataset Tag Editor 插件

对比一整段文本的描述,标签适合进行批量的筛选和编辑

配置 tag editor 开始自动打标
输入图片文件夹路径,选择 wd-v1-4-vit-tagger 模型。
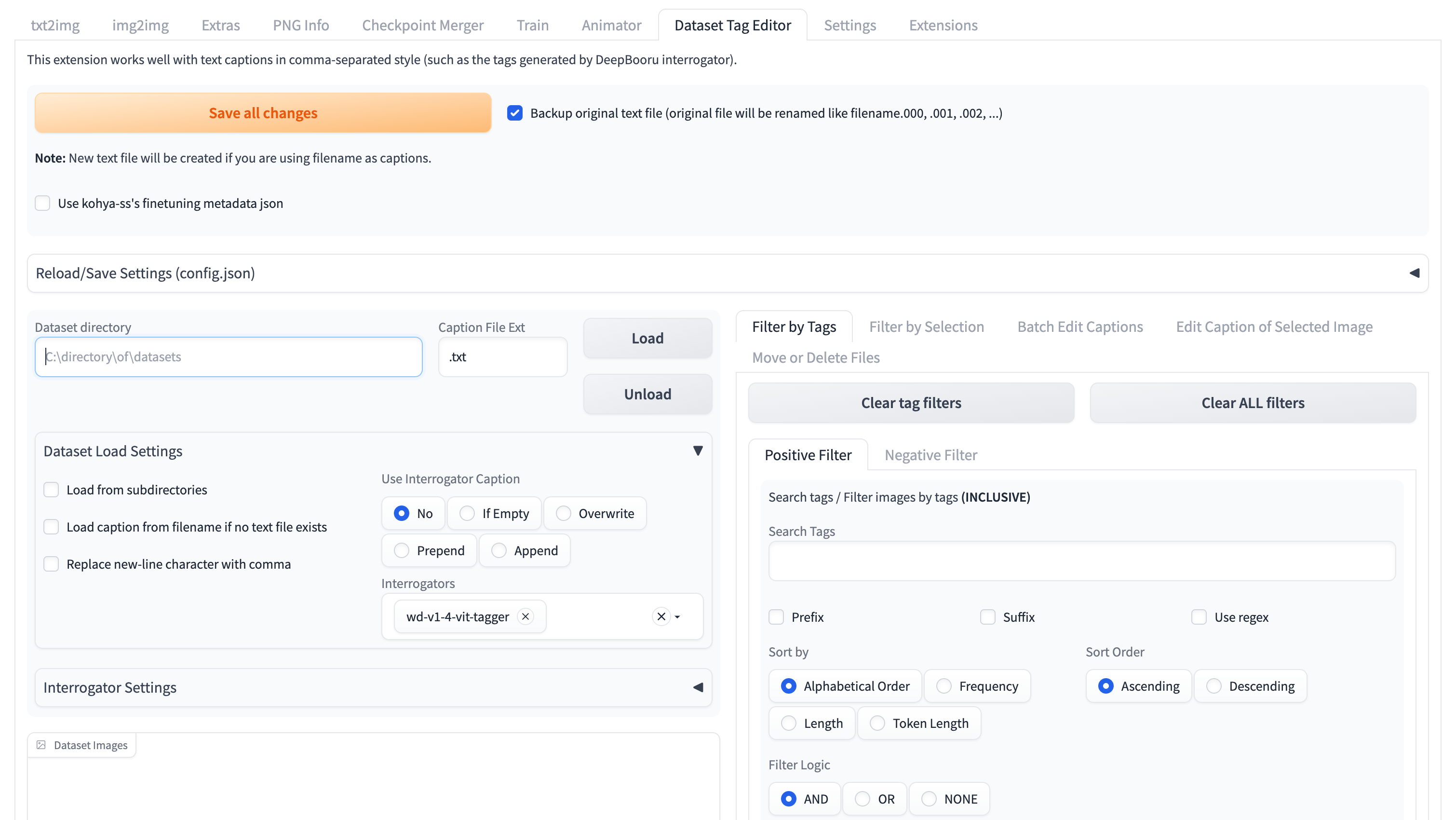
点击 "Load" 进行图片加载和自动打标签,右侧的工具可以对标签进行筛选和批量编辑。
点击 "Save all changes" 将标签保存到本地,为每一个图片生成一个对应的 txt 文件,包含了图片的标签,整个文件夹可用于下一步的模型训练。

4)利用 GPT4, GPT4V 和人工进一步调优标签
举个例子:

4. 模型训练
1)配置 LoRA-scripts (SD-Trainer) 工具
下载 https://github.com/Akegarasu/lora-scripts 运行"启动脚本.bat"后,在浏览器打开 http://127.0.0.1:28000/lora/basic.html

参数说明:
pretrained_model_name_or_path
基础模型的路径,这里可以放 sdwebui 工具里面某个模型的地址
train_data_dir
训练数据的目录,这里要填写训练数据文件夹的父目录,比如这里的 train/data
然后 train/data 目录下训练数据文件夹命名规则是 [n]_[name],n 表示文件夹里面的每个图片复制 n 份(适用于数据量较少的情况),name 表示模型的触发词,生成的时候需要在 prompt 中包含这个词

train/data/2_cafe 目录下的内容如上,也就上个阶段 tag editor 插件输出的数据
output_name
模型的名字,比如 cafe
output_dir
模型输出的目录,比如 output
save_every_n_epochs
每隔几个 epochs 保存一个模型的中间结果,比如 2
2)开始训练
训练步数 (Training Steps) = 轮数 (Epochs) * 图片数量。
如果设置了 save_every_n_epochs 则每 n 个 epochs 结束后会保存一个模型,方便后面做效果测试。
如果显卡较大,可以设置 > 1 的批次 (Batch Size),这样每一步可以同时训练多张图,加快训练。
结合上一步设置的参数,最终输出的模型样例如下,每一个文件就是一个 LoRA 模型。

5. 效果测试
利用 sdwebui 默认集成的 xyz plot 工具 (https://github.com/zer0TF/xyz_plot_script) 可以一次性查看不同 LoRA 权重和不同 Epoch 产生的 LoRA 模型生成的效果,以进一步调优训练参数。
1)准备提示词
借助 MuseAI 的提示词助手,输入需求,生成适合 Stable Diffusion 模型的提示词,稍作微调后可以在 sdwebui 中使用。

2)配置 XYZ Plot 工具
常规的融合 LoRA 模型的方式是在 prompt 中加入 <lora:[name]> 这样的标识,比如这里是使用名字为 “cafe-1” 的 LoRA 模型系列。
使用 XYZ Plot 工具的时候,需要把这个标识改成 <lora:[name]-MODAL:WEIGHT>, 其中 MODAL 和 WEIGHT 是占位符,以便被 XYZ Plot 工具替换成动态的参数。
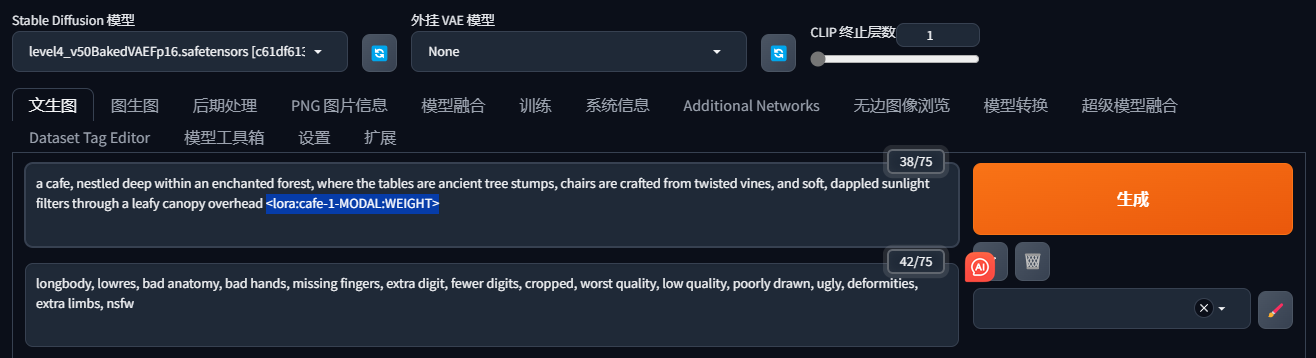
设置 X/Y 轴的类型为 Prompt S/R,Z 轴的类型不要设置,同时设置 MODAL 和 WEIGHT 的取值。
下面的例子中:MODAL 取值是 000002, 000004, ..., 这个对应前面步骤生成的模型上的 epoch 标记;WEIGHT 的取值是 0.4, 0.6, ..., 1。

3)生成结果
对比不同的 Epoch 里产生的模型及对应的模型权重,看哪个效果是最好的。
点击生成以后,sdwebui 会依次生成多张图,并且在一个平面上展示,例如:

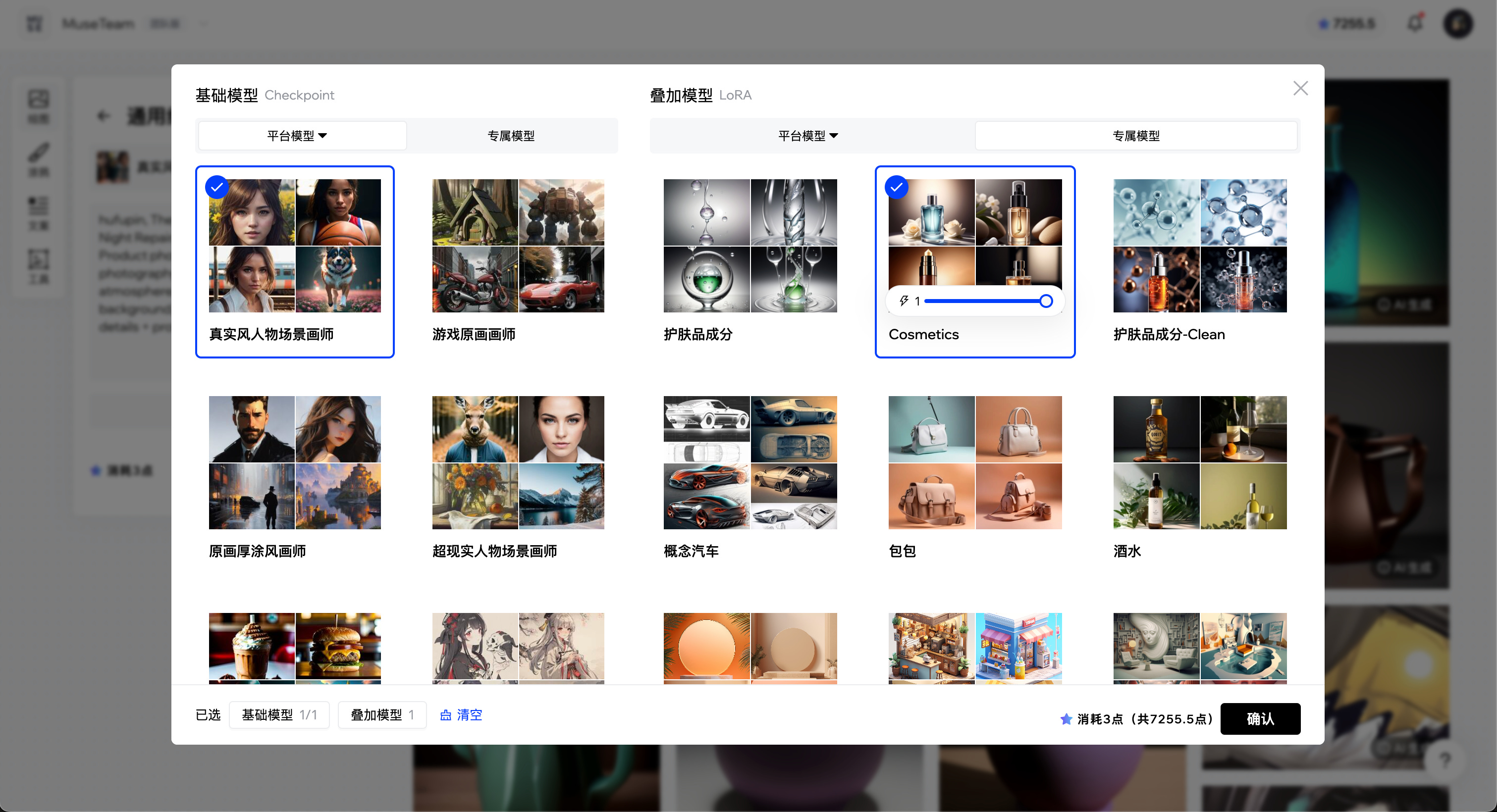
模型的使用
可使用 MuseAI 的的专属模型 - 模型管理,来管理本地训练的 LoRA 模型,并可叠加平台上其他的基础模型或 LoRA 模型进行使用:https://app.museai.cc/
上传模型

分享模型
可设置模型的封面图、以及用该模型作画的示例作品

以下是一个美妆护肤品的 LoRA 模型分析示例:
https://app.museai.cc/share/model/clktnibkb01qzmj4b2scjbpa2#「Cosmetics」模型分享

使用模型
包含所有生成参数,方便其他人一键生成同款

可叠加平台上其他的基础模型或 LoRA 模型进行生成